
Hay algo que rara vez se dice en voz alta dentro de las organizaciones: a todos nos gusta secretamente que no ocurra nada. Que no haya brechas. Que no haya ransomware. Que nadie haga clic donde no debe. Se entiende, pero es poco realista.
ISO 27001 y NIS2 parten de una idea mucho más madura: los incidentes ocurrirán. La diferencia no está en evitarlos, sino en cómo reaccionamos cuando llegan. Y, sobre todo, en si somos capaces de demostrar que reaccionamos con criterio, control y evidencias a posteriori.
Paso 0. Antes del incidente
Uno de los mayores errores es pensar que la gestión de incidentes comienza en el momento en que alguien detecta que hay un problema. En realidad, empieza mucho antes. Empieza cuando la organización ha tomado decisiones claras sobre cómo va a actuar el día que ese problema aparezca: quién recibe la notificación inicial, quién la analiza y la clasifica, quién tiene la autoridad para decidir los siguientes pasos y bajo qué criterios, y de qué manera se va a registrar cada acción y cada evidencia.
Si todo eso no está definido de antemano, el primer incidente serio no será solo un incidente de seguridad; será, además, un episodio de desorden organizativo. Habrá dudas sobre responsabilidades, retrasos en la toma de decisiones, mensajes contradictorios y, probablemente, una trazabilidad incompleta de lo ocurrido. Y en materia de ciberseguridad, el desorden multiplica el impacto.
Por eso, marcos como ISO 27001 no se limitan a recomendar buenas prácticas, sino que exigen la existencia de un proceso formal de gestión de incidentes. Y normativas como NIS2 van un paso más allá: no solo requieren que ese proceso exista sobre el papel, sino que funcione en la práctica y que la organización sea capaz de demostrarlo con evidencias claras, registros y resultados medibles.
Pero hay algo más: bajo NIS2, la responsabilidad no es únicamente técnica. La alta dirección y, en su caso, el consejo de administración, deben poder demostrar que han supervisado, entendido y respaldado el sistema de gestión de incidentes. No se trata solo de tener un procedimiento; se trata de asumir gobernanza real sobre cómo se gestiona el riesgo.
Paso 1. Detectar: alguien debe poder levantar la mano
Todo suele empezar con algo pequeño. Un comportamiento extraño que no encaja del todo, un acceso fuera de horario que llama la atención, un sistema que responde más lento de lo habitual sin una razón aparente. Señales débiles, casi imperceptibles, que podrían ser una simple anomalía… o el inicio de algo mayor.
La persona que lo detecta no tiene que saber si es grave, ni confirmar si realmente se trata de un incidente. Su responsabilidad no es diagnosticar, sino saber dónde avisar. Y ese detalle, que parece menor, transforma por completo la cultura de la organización.
Cuando las personas entienden que reportar no es “meterse en problemas”, sino formar parte activa del sistema de protección, la organización gana resiliencia. Se reduce el tiempo de reacción, se evitan silencios innecesarios y se construye una red de alerta temprana mucho más eficaz que cualquier herramienta tecnológica por sí sola.
La mejor forma para detectar es disponer de un formulario público para detectar e identificar las incidencias lo antes posible. Una buena alternativa es el módulo Incident Manager de ithikios.
Paso 2. Evaluar: parar, pensar, clasificar
En este segundo paso es donde empieza la madurez. No se trata de reaccionar con dramatismo ni de correr sin dirección. Se trata, simplemente, de detenerse un momento y hacerse dos preguntas muy concretas: qué impacto puede tener el incidente y con qué urgencia debemos actuar.
Parece obvio, pero en este punto muchas organizaciones tropiezan: empiezan a ejecutar acciones antes de haber clasificado lo que está ocurriendo. Se “hace algo” por inercia, por presión o por miedo a quedarse parados. El problema llega después, cuando alguien pregunta por qué se tomaron determinadas medidas, por qué se escaló, por qué se aisló un sistema, por qué se comunicó —o no se comunicó—. Y entonces no hay una respuesta estructurada, solo explicaciones improvisadas.
ISO 27001 insiste en que exista un proceso. NIS2 pone el foco en que haya una evaluación razonada. En la práctica, eso significa que cada decisión debe poder explicarse con serenidad: qué se sabía en ese momento, cómo se valoró el impacto, por qué se consideró urgente (o no) y cómo esa clasificación llevó a la acción. No como un ejercicio burocrático, sino como la base de una respuesta coherente y defendible ante auditores, autoridades o el propio consejo.
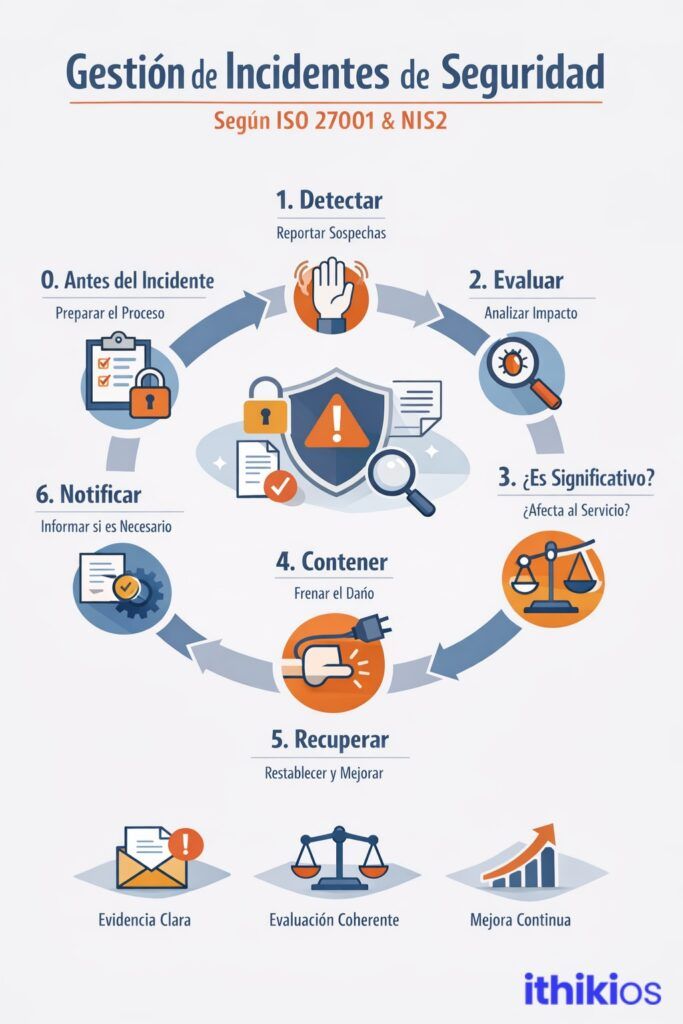
Paso 3. ¿Es significativo bajo NIS2? La pregunta incómoda
Aquí entra en juego la dimensión regulatoria. No todos los incidentes deben notificarse, y eso es importante entenderlo. Pero algunos sí. Y el verdadero riesgo no está en notificar cuando corresponde, sino en no saber justificar por qué decidiste no hacerlo.
La Directiva NIS2 introduce el concepto de incidente significativo y establece criterios concretos para determinarlo: el impacto financiero que puede generar, la afectación a servicios esenciales, la existencia de accesos maliciosos relevantes o la gravedad de las interrupciones provocadas.
En la práctica, la pregunta es sencilla: ¿ha afectado —o puede afectar— a la continuidad del servicio, a datos sensibles, a un número relevante de usuarios o a terceros?
Estos elementos ayudan a objetivar la decisión, a evitar que dependa únicamente de percepciones o intuiciones.
Sin embargo, más importante que el propio criterio es el razonamiento documentado que hay detrás. La clave no es solo concluir si algo es o no significativo, sino poder explicar por qué. Qué información se analizó, qué impacto se valoró, qué umbrales se consideraron y cómo se llegó a esa conclusión.
Incluso cuando decides que un incidente no es significativo, esa decisión debe quedar registrada. Porque bajo NIS2, la ausencia de evidencia no implica que actuaste correctamente; implica que no puedes demostrarlo. Y en el ámbito regulatorio, lo que no se puede demostrar, simplemente no existe.
Paso 4. Contener: primero que deje de empeorar
Contener no es arreglar. Es, simplemente, impedir que el daño siga creciendo. A veces significa aislar un sistema comprometido. O revocar credenciales que podrían estar expuestas. O incluso desconectar temporalmente un servicio para cortar la propagación. Son decisiones incómodas, tomadas en medio de la presión y el ruido.
Y es precisamente en ese contexto cuando resulta más fácil olvidar algo esencial: registrar lo que se está haciendo. La prioridad es actuar, proteger, estabilizar. Documentar nos puede parecer secundario. Pero lo que no se deja por escrito en caliente, rara vez puede reconstruirse en frío.
Y, cuando sea posible, preservar evidencias antes de “limpiar” el sistema: logs, snapshots, correos, hashes, capturas o cualquier elemento que permita reconstruir lo ocurrido con rigor.
Cada acción debería dejar un rastro claro: quién tomó la decisión, en qué momento, qué medida concreta se aplicó y con qué objetivo. No como un mecanismo defensivo ni como un ejercicio burocrático, sino como una herramienta de comprensión. Porque cuando todo pase, lo que permitirá aprender —y mejorar— no será solo lo que se hizo, sino la capacidad de entender por qué se hizo.
Paso 5. Recuperar: volver, pero mejor
Recuperar no significa volver cuanto antes. Significa volver con criterio. No se trata solo de restablecer sistemas y reanudar operaciones, sino de hacerlo habiendo corregido aquello que permitió que el incidente ocurriera.
Si existía una vulnerabilidad, debe corregirse antes de reactivar completamente el entorno. Si hubo credenciales comprometidas, deben rotarse y revisarse los mecanismos de autenticación. Si se evidenció una debilidad estructural, debe reforzarse. De lo contrario, lo que llamamos “recuperación” no es más que una pausa antes del siguiente incidente.
Aquí aparece una paradoja frecuente: muchas organizaciones gestionan razonablemente bien la urgencia, pero descuidan el aprendizaje. Se centran en apagar el fuego y celebran cuando todo vuelve a funcionar, pero no dedican el mismo rigor a analizar qué falló, qué señales se ignoraron o qué decisiones podrían haberse tomado mejor.
ISO 27001 insiste en la necesidad de extraer lecciones aprendidas por una razón muy simple: los incidentes tienden a repetirse. Cambian los detalles, pero no siempre las causas profundas. Si no conviertes cada incidente en un input estructurado para tu sistema de mejora continua, el siguiente no solo llegará, sino que probablemente será más costoso y más difícil de justificar ante la dirección o la autoridad.
Paso 6. Notificar (si aplica): cuando el incidente ya no es solo tuyo
Hay un momento en que el incidente deja de ser un asunto exclusivamente interno. Bajo la directiva NIS2, determinados incidentes deben notificarse a la autoridad competente dentro de plazos concretos. Y ese requisito cambia por completo la conversación.
A partir de ahí, ya no basta con haber contenido técnicamente la situación. Empieza a importar cómo clasificaste el incidente, en qué momento consideraste que tenías conocimiento razonable de su alcance, qué medidas adoptaste desde ese instante y cómo evaluaste el impacto real o potencial. La narrativa técnica se convierte también en una narrativa de gestión y de responsabilidad.
Y aquí la dirección ya no puede ser espectadora. Debe estar en condiciones de respaldar la decisión de notificar —o de no hacerlo— con criterios claros y documentados. Porque las consecuencias no son únicamente técnicas; pueden ser regulatorias, reputacionales o económicas.
Incluso si decides no notificar, la exigencia es la misma: debes poder justificar esa decisión con igual solvencia. Qué criterios aplicaste, qué información analizaste y por qué concluiste que no alcanzaba el umbral de notificación.
Es en este punto donde se pone verdaderamente a prueba la gobernanza.
Paso 7. Cerrar formalmente: que no desaparezca en silencio
Cuando todo parece haber vuelto a la normalidad, la tentación natural es pasar página y seguir adelante. Pero ahí es donde muchas organizaciones fallan. Podríamos decir que un incidente que no se cierra formalmente es, en realidad, un incidente no terminado.
El cierre no es un trámite administrativo; es un ejercicio de rigor. Implica analizar la causa raíz y no conformarse con los síntomas visibles. Supone dejar constancia de qué decisiones se tomaron y por qué, cuánto tiempo se tardó en detectar, contener y recuperar, qué acciones correctivas se definieron y qué mejoras concretas se implementaron para reducir la probabilidad de repetición.
Y, sobre todo, ese cierre debe alimentar el sistema. Debe traducirse en ajustes reales en procedimientos, controles, formación o tecnologías. Si la experiencia no modifica nada, entonces no hubo aprendizaje, solo resolución.
En conclusión: no se trata de evitar incidentes
ISO/IEC 27001 y NIS2 no exigen sistemas perfectos. Exigen organizaciones responsables. Organizaciones que asumen que los incidentes no son una anomalía improbable, sino una posibilidad real. Que se preparan antes de que ocurran. Que, cuando suceden, actúan con método en lugar de improvisación. Y que, pasado el tiempo, pueden explicar con serenidad qué ocurrió, cómo respondieron y qué aprendieron.
Gestionar bien un incidente no significa hacerlo invisible ni minimizarlo hasta que parezca irrelevante. Significa hacerlo comprensible para quien deba analizarlo después. Significa que sea trazable en cada decisión y en cada acción. Y, sobre todo, que resulte útil para fortalecer el sistema a futuro.
Y significa que cada incidente se convierta en un plan de mejora: acciones concretas, responsables, plazos y seguimiento.
La diferencia entre una organización vulnerable y una organización madura no es la ausencia de incidentes. Es la calidad de sus decisiones cuando nadie tiene todas las respuestas.
Cuando eso ocurre, el incidente deja de ser únicamente un problema superado. Se convierte en algo más valioso: una confirmación de que el sistema de gestión no es decorativo, sino que funciona en la práctica, incluso bajo presión.

