
There is something that is rarely said out loud within organizations: we all secretly like it when nothing happens. No breaches. No ransomware. That no one clicks where they shouldn’t. It’s understandable, but unrealistic.
ISO 27001 and NIS2 start from a much more mature idea: incidents will happen. The difference is not in avoiding them, but in how we react when they do occur. And, above all, in whether we are able to demonstrate that we react with criteria, control and evidence a posteriori.
Step 0. Before the incident
One of the biggest mistakes is to think that incident management starts the moment someone detects that there is a problem. In reality, it starts much earlier. It starts when the organization has made clear decisions about how it will act on the day that problem appears: who receives the initial notification, who analyzes and classifies it, who has the authority to decide the next steps and under what criteria, and how each action and each piece of evidence will be recorded.
If all this is not defined beforehand, the first serious incident will not only be a security incident; it will also be an episode of organizational disorder. There will be doubts about responsibilities, delays in decision-making, contradictory messages and, probably, incomplete traceability of what happened. And in cybersecurity, disorder multiplies the impact.
For this reason, frameworks such as ISO 27001 do not limit themselves to recommending good practices, but require the existence of a formal incident management process. And standards such as NIS2 go a step further: they not only require that this process exists on paper, but that it works in practice and that the organization is able to demonstrate it with clear evidence, records and measurable results.
But there’s more: under NIS2, accountability is not just technical. Senior management and, where appropriate, the board of directors, must be able to demonstrate that they have overseen, understood and supported the incident management system. It’s not just about having a procedure; it’s about taking real governance over how risk is managed.
Step 1. Detect: someone must be able to raise his or her hand.
It all usually starts with something small. A strange behavior that doesn’t quite fit, an after-hours access that catches your attention, a system that responds slower than usual for no apparent reason. Faint, almost imperceptible signals that could be a simple anomaly… or the start of something bigger.
The person who detects it does not have to know if it is serious, nor confirm if it is really an incident. Their responsibility is not to diagnose, but to know where to report it. And this seemingly minor detail completely transforms the culture of the organization.
When people understand that reporting is not “getting into trouble” but being an active part of the protection system, the organization gains resilience. Reaction time is reduced, unnecessary silences are avoided, and an early warning network is built that is much more effective than any technological tool alone.
The best way to detect is to have a public form to detect and identify incidents as soon as possible. A good alternative is the ithikios Incident Manager module.
Step 2. Evaluate: stop, think, sort
This second step is where maturity begins. It is not about reacting dramatically or running without direction. It is simply a matter of stopping for a moment and asking two very specific questions: what impact the incident may have and how urgently we need to act.
It seems obvious, but at this point many organizations stumble: they start to execute actions before having classified what is happening. They “do something” out of inertia, pressure or fear of standing still. The problem comes later, when someone asks why certain actions were taken, why it was escalated, why a system was isolated, why it was communicated -or not communicated-. And then there is no structured answer, only improvised explanations.
ISO 27001 insists that there is a process. NIS2 focuses on a reasoned assessment. In practice, that means that each decision must be able to be explained in a straightforward manner: what was known at the time, how the impact was assessed, why it was considered urgent (or not) and how that rating led to action. Not as a bureaucratic exercise, but as the basis for a coherent and defensible response to auditors, authorities or the board itself.
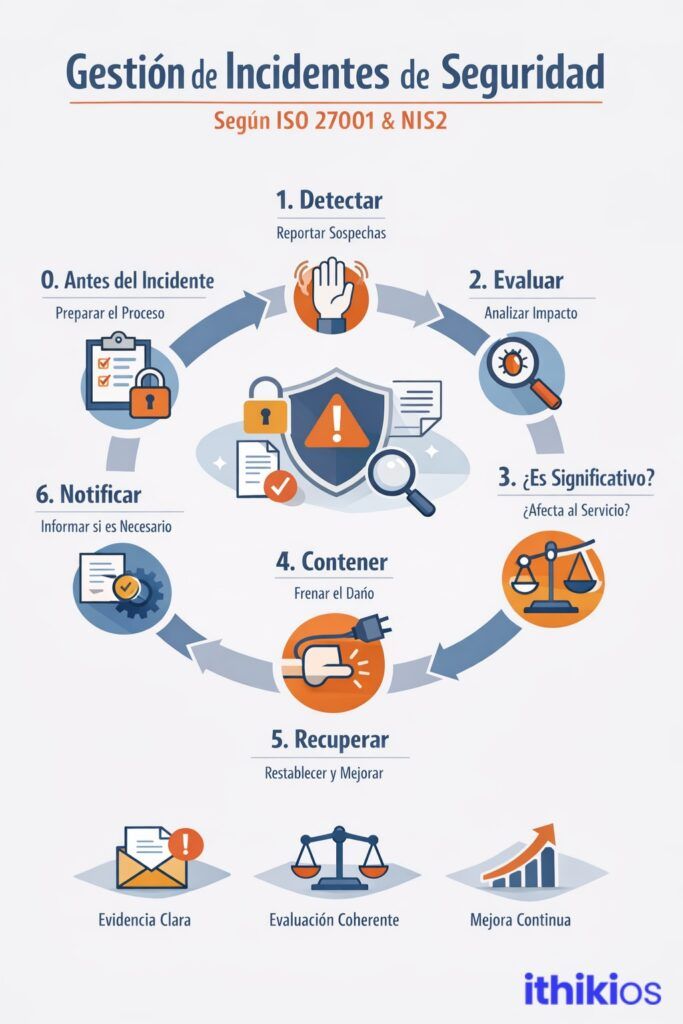
Step 3. Is it meaningful under NIS2? The awkward question
This is where the regulatory dimension comes into play. Not all incidents must be notified, and that is important to understand, but some do. And the real risk is not in notifying when it is due, but in not knowing how to justify why you decided not to do so.
The NIS2 Directive introduces the concept of significant incident and establishes specific criteria for determining it: the financial impact it may generate, the impact on essential services, the existence of relevant malicious access or the seriousness of the interruptions caused.
In practice, the question is simple: has it affected – or can it affect – the continuity of the service, sensitive data, a relevant number of users or third parties?
These elements help to objectify the decision, to prevent it from depending solely on perceptions or intuitions.
However, more important than the criterion itself is the documented reasoning behind it. The key is not only to be able to conclude whether or not something is significant, but to be able to explain why. What information was analyzed, what impact was assessed, what thresholds were considered and how that conclusion was reached.
Even when you decide that an incident is not significant, that decision must be recorded. Because under NIS2, the absence of evidence doesn’t imply that you acted correctly; it implies that you can’t prove it. And in the regulatory arena, what you can’t prove simply doesn’t exist.
Step 4. Contain: first stop worsening
To contain is not to fix. It is simply preventing the damage from continuing to grow. Sometimes it means isolating a compromised system. Or revoking credentials that might be exposed. Or even temporarily disconnecting a service to cut off the spread. These are uncomfortable decisions, made in the midst of pressure and noise.
And it is precisely in this context that it is easy to forget something essential: to record what is being done. The priority is to act, to protect, to stabilize. Documenting may seem secondary to us. But what is not written down in the heat of the moment can rarely be reconstructed in the cold.
And, whenever possible, preserve evidence before “cleaning” the system: logs, snapshots, emails, hashes, captures or any element that allows to reconstruct what happened with rigor.
Every action should leave a clear trace: who made the decision, at what time, what concrete measure was applied and for what purpose. Not as a defensive mechanism or as a bureaucratic exercise, but as a tool for understanding. Because when everything passes, what will allow us to learn -and improve- will not only be what was done, but the ability to understand why it was done.
Step 5. Recover: back, but better
To recover does not mean to come back as soon as possible. It means coming back judiciously. It is not just about restoring systems and resuming operations, but doing so having corrected what allowed the incident to occur.
If a vulnerability existed, it should be corrected before fully reactivating the environment. If credentials were compromised, authentication mechanisms should be rotated and reviewed. If a structural weakness was evident, it must be strengthened. Otherwise, what we call “recovery” is nothing more than a pause before the next incident.
A frequent paradox arises here: many organizations manage urgency reasonably well, but neglect learning. They focus on putting out the fire and celebrate when everything works again, but do not devote the same rigor to analyzing what went wrong, what signals were ignored or what decisions could have been made better.
ISO 27001 insists on the need to extract lessons learned for a very simple reason: incidents tend to repeat themselves. The details change, but not always the root causes. If you don’t turn each incident into a structured input to your continual improvement system, the next one will not only come, but will probably be more costly and harder to justify to management or authority.
Step 6. Notify (if applicable): when the incident is no longer yours alone.
There is a point at which the incident is no longer an exclusively internal matter. Under the NIS2 directive, certain incidents must be reported to the competent authority within specific deadlines. And that requirement completely changes the conversation.
From that point on, it is no longer enough to have technically contained the situation. It starts to matter how you classified the incident, at what point you considered you had reasonable knowledge of its scope, what actions you took from that point on, and how you assessed the actual or potential impact. The technical narrative also becomes a management and accountability narrative.
And here management can no longer be a spectator. It must be in a position to support the decision to notify – or not to notify – with clear and documented criteria. Because the consequences are not only technical; they can be regulatory, reputational or economic.
Even if you decide not to notify, the requirement is the same: you must be able to justify that decision equally well. What criteria you applied, what information you analyzed and why you concluded that it did not meet the notification threshold.
It is at this point that governance is truly put to the test.
Step 7. Close formally: don’t let it disappear quietly
When everything seems to be back to normal, the natural temptation is to turn the page and move on. But that’s where many organizations fail. We could say that an incident that is not formally closed is, in reality, an unfinished incident.
Closure is not an administrative procedure; it is a rigorous exercise. It involves analyzing the root cause and not settling for the visible symptoms. It involves recording what decisions were made and why, how long it took to detect, contain and recover, what corrective actions were defined and what concrete improvements were implemented to reduce the likelihood of recurrence.
And, above all, this closure must feed the system. It must translate into real adjustments in procedures, controls, training or technologies. If the experience does not change anything, then there was no learning, only resolution.
In conclusion: it is not a matter of avoiding incidents
ISO/IEC 27001 and NIS2 do not demand perfect systems. They demand responsible organizations. Organizations that assume that incidents are not an unlikely anomaly, but a real possibility. That prepare before they happen. That, when they happen, they act with method rather than improvisation. And that, in time, can calmly explain what happened, how they responded and what they learned.
Managing an incident well does not mean making it invisible or minimizing it until it seems irrelevant. It means making it understandable to whoever has to analyze it afterwards. It means making it traceable in every decision and every action. And, above all, it means making it useful to strengthen the system in the future.
And it means turning every incident into an improvement plan: concrete actions, responsible parties, deadlines and follow-up.
The difference between a vulnerable organization and a mature organization is not the absence of incidents. It is the quality of its decisions when no one has all the answers.
When that happens, the incident is no longer just a problem overcome. It becomes something more valuable: a confirmation that the management system is not decorative, but works in practice, even under pressure.

