
Há algo que raramente é dito em voz alta nas organizações: todos nós gostamos secretamente quando nada acontece. Não há violações. Não há ransomware. Que ninguém clique onde não deve. É compreensível, mas irrealista.
A ISO 27001 e a NIS2 partem de uma ideia muito mais madura: os incidentes vão acontecer. A diferença não está em evitá-los, mas na forma como reagimos quando eles acontecem. E, acima de tudo, se somos capazes de demonstrar que reagimos com discernimento, controlo e provas após o evento.
Passo 0. Antes do incidente
Um dos maiores erros é pensar que a gestão de incidentes começa no momento em que alguém detecta que existe um problema. Na realidade, começa muito antes. Começa quando a organização tiver tomado decisões claras sobre a forma como irá atuar no dia em que o problema surgir: quem recebe a notificação inicial, quem a analisa e classifica, quem tem autoridade para decidir os passos seguintes e segundo que critérios, e como cada ação e prova será registada.
Se isto não for definido antecipadamente, o primeiro incidente grave não será apenas um incidente de segurança, mas também um episódio de desordem organizacional. Haverá dúvidas sobre as responsabilidades, atrasos na tomada de decisões, mensagens contraditórias e, provavelmente, uma rastreabilidade incompleta do que aconteceu. E, em matéria de cibersegurança, a desordem multiplica o impacto.
É por isso que estruturas como a ISO 27001 não se limitam a recomendar boas práticas, mas exigem a existência de um processo formal de gestão de incidentes. E normas como a NIS2 vão um passo mais além: exigem não só que esse processo exista no papel, mas que funcione na prática e que a organização seja capaz de o demonstrar com provas claras, registos e resultados mensuráveis.
Mas há mais: ao abrigo da NIS2, a responsabilidade não é apenas técnica. A gestão de topo e, quando apropriado, o conselho de administração, devem ser capazes de demonstrar que supervisionaram, compreenderam e apoiaram o sistema de gestão de incidentes. Não se trata apenas de ter um procedimento; trata-se de assumir uma verdadeira governação sobre a forma como o risco é gerido.
Passo 1 – Detetar: alguém tem de poder levantar a mão.
Normalmente, tudo começa com algo pequeno. Um comportamento estranho que não se encaixa, um acesso fora de horas que chama a tua atenção, um sistema que responde mais lentamente do que o habitual sem razão aparente. Sinais ténues, quase imperceptíveis, que podem ser uma simples anomalia… ou o início de algo maior.
A pessoa que o detecta não tem de saber se é grave, nem tem de confirmar se se trata realmente de um incidente. A sua responsabilidade não é diagnosticar, mas sim saber onde o deve reportar. E este pormenor, aparentemente insignificante, transforma completamente a cultura da organização.
Quando as pessoas compreendem que denunciar não é “meter-se em sarilhos”, mas sim ser uma parte ativa do sistema de proteção, a organização torna-se mais resistente. Reduz o tempo de reação, evita silêncios desnecessários e cria uma rede de alerta precoce que é muito mais eficaz do que qualquer ferramenta tecnológica.
A melhor maneira de detetar é ter um formulário público para detetar e identificar incidentes o mais cedo possível. Uma boa alternativa é o módulo de gestão de incidentes do ithikios.
Passo 2. Avalia: pára, pensa, classifica
Este segundo passo é onde começa a maturidade. Não se trata de reagir de forma dramática ou de correr sem direção. É simplesmente uma questão de parar por um momento e fazer duas perguntas muito específicas: qual o impacto que o incidente poderá ter e com que urgência temos de agir.
Parece óbvio, mas neste ponto muitas organizações tropeçam: começam a implementar acções antes de terem percebido o que está a acontecer. Faz algo por inércia, por pressão ou por medo de ficar parado. O problema surge mais tarde, quando alguém pergunta porque é que certas acções foram tomadas, porque é que foi escalado, porque é que um sistema foi isolado, porque é que foi comunicado – ou não foi comunicado – e depois não há uma resposta estruturada, apenas explicações improvisadas.
A ISO 27001 insiste num processo. A NIS2 centra-se numa avaliação fundamentada. Na prática, isto significa que cada decisão deve poder ser explicada de forma simples: o que se sabia na altura, como foi avaliado o impacto, porque foi considerada urgente (ou não) e como essa classificação levou à ação. Não como um exercício burocrático, mas como a base de uma resposta coerente e defensável aos auditores, às autoridades ou ao próprio conselho de administração.
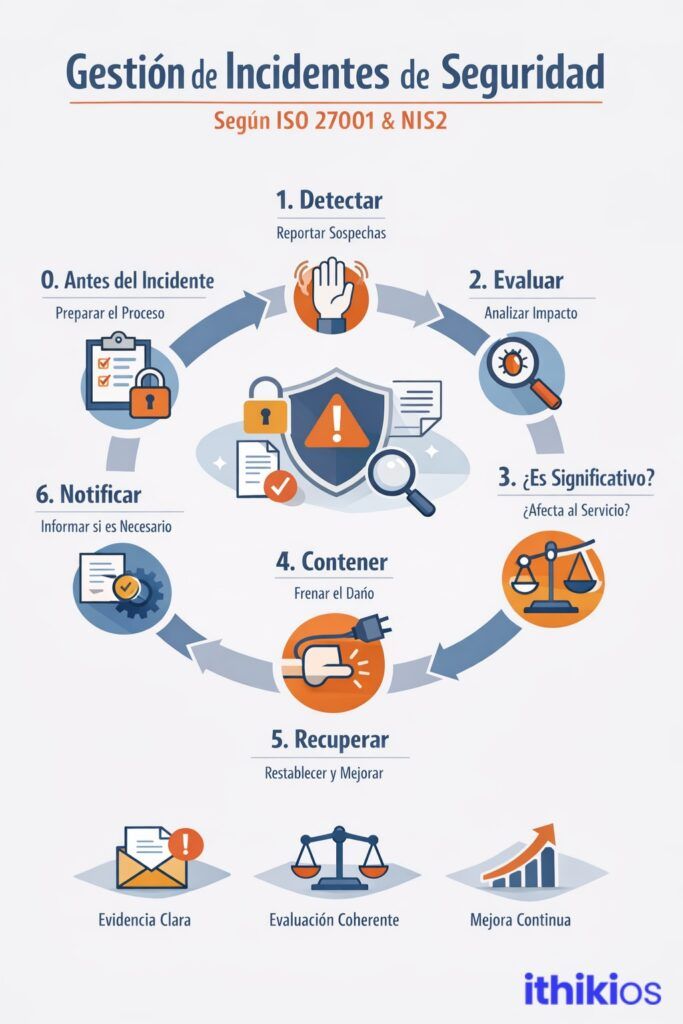
Passo 3: Faz sentido no NIS2? A pergunta incómoda
É aqui que entra em jogo a dimensão regulamentar. Nem todos os incidentes precisam de ser notificados, e é importante compreender isso, mas alguns precisam. E o verdadeiro risco não está em notificar quando é devido, mas em não saber como justificar a razão pela qual decidiste não o fazer.
A Diretiva SRI2 introduz o conceito de incidente significativo e estabelece critérios específicos para a sua determinação: o impacto financeiro que pode gerar, o impacto nos serviços essenciais, a existência de acesso malicioso relevante ou a gravidade das perturbações causadas.
Na prática, a questão é simples: afectou – ou é suscetível de afetar – a continuidade do serviço, os dados sensíveis, um número relevante de utilizadores ou terceiros?
Estes elementos ajudam a objetivar a decisão, para que esta não dependa apenas de percepções ou intuições.
No entanto, mais importante do que o critério em si, é o raciocínio documentado que lhe está subjacente. A chave não é apenas concluir se algo é ou não significativo, mas ser capaz de explicar porquê. Que informação foi analisada, que impacto foi avaliado, que limiares foram considerados e como se chegou a essa conclusão.
Mesmo quando decides que um incidente não é significativo, essa decisão deve ser registada. Porque, nos termos da NIS2, a ausência de provas não implica que tenhas agido corretamente; implica que não o podes provar. E no domínio da regulamentação, o que não pode ser provado simplesmente não existe.
Passo 4. Contém: primeiro pára o agravamento
Conter não é reparar. Simplesmente evita que o dano cresça. Por vezes, significa isolar um sistema comprometido. Ou revogar as credenciais que podem ser expostas. Ou mesmo desligar temporariamente um serviço para cortar a propagação. Estas são decisões incómodas, tomadas no meio da pressão e do ruído.
E é precisamente neste contexto que é mais fácil esquecer algo essencial: registar o que está a ser feito. A prioridade é agir, proteger, estabilizar. Documentar pode parecer secundário. Mas o que não é escrito no calor do momento raramente pode ser reconstruído no frio.
E, sempre que possível, preserva as provas antes de “limpar” o sistema: logs, snapshots, e-mails, hashes, capturas ou qualquer elemento que permita uma reconstrução rigorosa do que aconteceu.
Cada ação deve deixar um rasto claro: quem tomou a decisão, em que momento, que medida concreta foi aplicada e com que objetivo. Não como um mecanismo de defesa ou um exercício burocrático, mas como um instrumento de compreensão. Porque quando tudo acabar, o que nos permitirá aprender – e melhorar – não é apenas o que foi feito, mas a capacidade de compreender porque é que foi feito.
Passo 5 – Recupera: de volta, mas melhor
Recuperar não significa regressar o mais rapidamente possível. Significa regressar de forma judiciosa. Não se trata apenas de restaurar sistemas e retomar operações, mas de o fazer tendo corrigido o que permitiu a ocorrência do incidente.
Se existir uma vulnerabilidade, esta deve ser corrigida antes de o ambiente ser totalmente reativado. Se as credenciais foram comprometidas, os mecanismos de autenticação devem ser rodados e revistos. Se uma fraqueza estrutural foi evidente, ela deve ser reforçada. Caso contrário, o que chamamos de “recuperação” é apenas uma pausa antes do próximo incidente.
Surge aqui um paradoxo frequente: muitas organizações gerem razoavelmente bem a urgência, mas negligenciam a aprendizagem. Concentram-se em apagar o fogo e festejam quando tudo volta a funcionar, mas não dedicam o mesmo rigor à análise do que correu mal, dos sinais que foram ignorados ou das decisões que poderiam ter sido tomadas de melhor forma.
A ISO 27001 insiste na necessidade de extrair lições aprendidas por uma razão muito simples: os incidentes tendem a repetir-se. Os pormenores mudam, mas nem sempre as causas principais. Se não transformares cada incidente num contributo estruturado para o teu sistema de melhoria contínua, o próximo não só virá, como será provavelmente mais dispendioso e mais difícil de justificar perante a gestão ou a autoridade.
Passo 6: Notificar (se aplicável): quando o incidente já não for só teu
Há um momento em que um incidente deixa de ser um assunto puramente interno. De acordo com a diretiva NIS2, certos incidentes devem ser comunicados à autoridade competente dentro de prazos específicos. E essa exigência muda toda a conversa.
Nesta altura, já não é suficiente ter contido tecnicamente a situação. Começa a importar a forma como classificaste o incidente, em que momento consideraste que tinhas um conhecimento razoável do seu âmbito, que acções tomaste a partir desse momento e como avaliaste o impacto real ou potencial. A narrativa técnica também se torna uma narrativa de gestão e responsabilidade.
E aqui a direção não pode continuar a ser um espetador. Tem de estar em posição de apoiar a decisão de notificar – ou não notificar – com critérios claros e documentados. Porque as consequências não são apenas técnicas; podem ser regulamentares, de reputação ou económicas.
Mesmo que decidas não notificar, o requisito é o mesmo: deves ser capaz de justificar igualmente bem essa decisão. Os critérios que aplicaste, as informações que analisaste e por que razão concluíste que não atingiam o limiar de notificação.
É aqui que a governação é realmente posta à prova.
Passo 7. Fecha formalmente: não o deixes desaparecer em silêncio
Quando tudo parece ter voltado ao normal, a tentação natural é virar a página e seguir em frente. Mas é aqui que muitas organizações falham. Pode dizer-se que um incidente que não está formalmente encerrado é, na realidade, um incidente inacabado.
O encerramento não é uma formalidade administrativa, é um exercício de rigor. Implica analisar a causa raiz e não se contentar com os sintomas visíveis. Implica registar que decisões foram tomadas e porquê, quanto tempo demorou a detetar, conter e recuperar, que acções corretivas foram definidas e que melhorias concretas foram implementadas para reduzir a probabilidade de recorrência.
E, acima de tudo, esse encerramento deve alimentar o sistema. Deve traduzir-se em ajustamentos reais dos procedimentos, controlos, formação ou tecnologias. Se a experiência não mudar nada, então não houve aprendizagem, apenas resolução.
Em conclusão: não se trata de evitar incidentes
A ISO/IEC 27001 e a NIS2 não exigem sistemas perfeitos. Exigem organizações responsáveis. Organizações que assumem que os incidentes não são uma anomalia improvável, mas uma possibilidade real. Que se preparem antes de eles acontecerem. Que, quando acontecem, actuam com método e não com improvisação. E que, a seu tempo, possam explicar calmamente o que aconteceu, como reagiram e o que aprenderam.
Gerir bem um incidente não significa torná-lo invisível ou minimizá-lo até parecer irrelevante. Significa torná-lo compreensível para quem tiver de o analisar posteriormente. Significa torná-lo rastreável em cada decisão e em cada ação. E, acima de tudo, significa torná-lo útil para reforçar o sistema no futuro.
E significa transformar cada incidente num plano de melhoria: acções concretas, responsáveis, prazos e acompanhamento.
A diferença entre uma organização vulnerável e uma organização madura não é a ausência de incidentes. É a qualidade das suas decisões quando ninguém tem todas as respostas.
Quando isso acontece, o incidente deixa de ser apenas um problema superado. Torna-se algo mais valioso: uma confirmação de que o sistema de gestão não é decorativo, mas funciona na prática, mesmo sob pressão.

