
Il y a quelque chose qui est rarement dit à voix haute au sein des organisations : nous aimons tous secrètement que rien ne se passe. Pas de violation. Pas de ransomware. Que personne ne clique là où il ne faut pas. C’est compréhensible, mais irréaliste.
Les normes ISO 27001 et NIS2 partent d’une idée beaucoup plus mûre : des incidents se produiront. La différence ne réside pas dans le fait de les éviter, mais dans la manière dont nous réagissons lorsqu’ils se produisent. Et, surtout, si nous sommes capables de démontrer que nous réagissons avec discernement, contrôle et preuves après l’événement.
Étape 0. Avant l’incident
L’une des plus grandes erreurs consiste à penser que la gestion des incidents commence dès que quelqu’un détecte un problème. En réalité, elle commence bien plus tôt. Elle commence lorsque l’organisation a pris des décisions claires sur la manière dont elle agira le jour où le problème apparaît : qui reçoit la notification initiale, qui l’analyse et la classe, qui a le pouvoir de décider des étapes suivantes et selon quels critères, et comment chaque action et chaque élément de preuve seront enregistrés.
Si cela n’est pas défini à l’avance, le premier incident grave ne sera pas seulement un incident de sécurité, mais aussi un épisode de désarroi organisationnel. Il y aura des doutes sur les responsabilités, des retards dans la prise de décision, des messages contradictoires et probablement une traçabilité incomplète de ce qui s’est passé. Et en matière de cybersécurité, le désordre multiplie l’impact.
C’est pourquoi des cadres tels que l’ISO 27001 ne se contentent pas de recommander de bonnes pratiques, mais exigent la mise en place d’un processus formel de gestion des incidents. Des normes telles que NIS2 vont encore plus loin : elles exigent non seulement qu’un tel processus existe sur papier, mais aussi qu’il fonctionne dans la pratique et que l’organisation soit en mesure de le démontrer par des preuves claires, des enregistrements et des résultats mesurables.
Mais ce n’est pas tout : dans le cadre du NIS2, la responsabilité n’est pas seulement technique. Les cadres supérieurs et, le cas échéant, le conseil d’administration doivent être en mesure de démontrer qu’ils ont supervisé, compris et soutenu le système de gestion des incidents. Il ne s’agit pas seulement d’avoir une procédure ; il s’agit d’exercer une véritable gouvernance sur la manière dont les risques sont gérés.
Étape 1 : Détection : quelqu’un doit pouvoir lever la main.
Tout commence généralement par une petite chose. Un comportement étrange qui ne colle pas, un accès en dehors des heures de bureau qui attire votre attention, un système qui réagit plus lentement que d’habitude sans raison apparente. Des signaux faibles, presque imperceptibles, qui peuvent être une simple anomalie… ou le début de quelque chose de plus grave.
La personne qui le détecte n’a pas à savoir s’il s’agit d’un incident grave, ni à confirmer qu’il s’agit bien d’un incident. Sa responsabilité n’est pas de poser un diagnostic, mais de savoir où le signaler. Et ce détail apparemment mineur transforme complètement la culture de l’organisation.
Lorsque les gens comprennent que le signalement n’est pas un moyen de « s’attirer des ennuis » mais de participer activement au système de protection, l’organisation devient plus résiliente. Elle réduit le temps de réaction, évite les silences inutiles et met en place un réseau d’alerte précoce bien plus efficace que n’importe quel outil technologique.
La meilleure façon de détecter les incidents est de disposer d’un formulaire public permettant de les détecter et de les identifier le plus tôt possible. Le module ithikios Incident Manager constitue une bonne alternative.
Étape 2. Évaluer : s’arrêter, réfléchir, trier
C’est au cours de cette deuxième étape que commence la maturité. Il ne s’agit pas de réagir de manière dramatique ou de courir sans direction. Il s’agit simplement de s’arrêter un instant et de se poser deux questions très précises : quel est l’impact probable de l’incident et quelle est l’urgence d’agir.
Cela semble évident, mais à ce stade, de nombreuses organisations trébuchent : elles commencent à mettre en œuvre des actions avant d’avoir compris ce qui se passe. Quelque chose est « fait » par inertie, par pression ou par peur de l’immobilisme. Le problème survient plus tard, lorsque quelqu’un demande pourquoi certaines actions ont été entreprises, pourquoi la situation a été portée à un niveau supérieur, pourquoi un système a été isolé, pourquoi cela a été communiqué – ou non communiqué – et qu’il n’y a pas de réponse structurée, mais seulement des explications improvisées.
La norme ISO 27001 insiste sur un processus. Le NIS2 met l’accent sur une évaluation raisonnée. En pratique, cela signifie que chaque décision doit pouvoir être expliquée de manière simple : ce qui était connu à l’époque, comment l’impact a été évalué, pourquoi il a été considéré comme urgent (ou non), et comment cette classification a conduit à l’action. Il ne s’agit pas d’un exercice bureaucratique, mais de la base d’une réponse cohérente et défendable aux auditeurs, aux autorités ou au conseil d’administration lui-même.
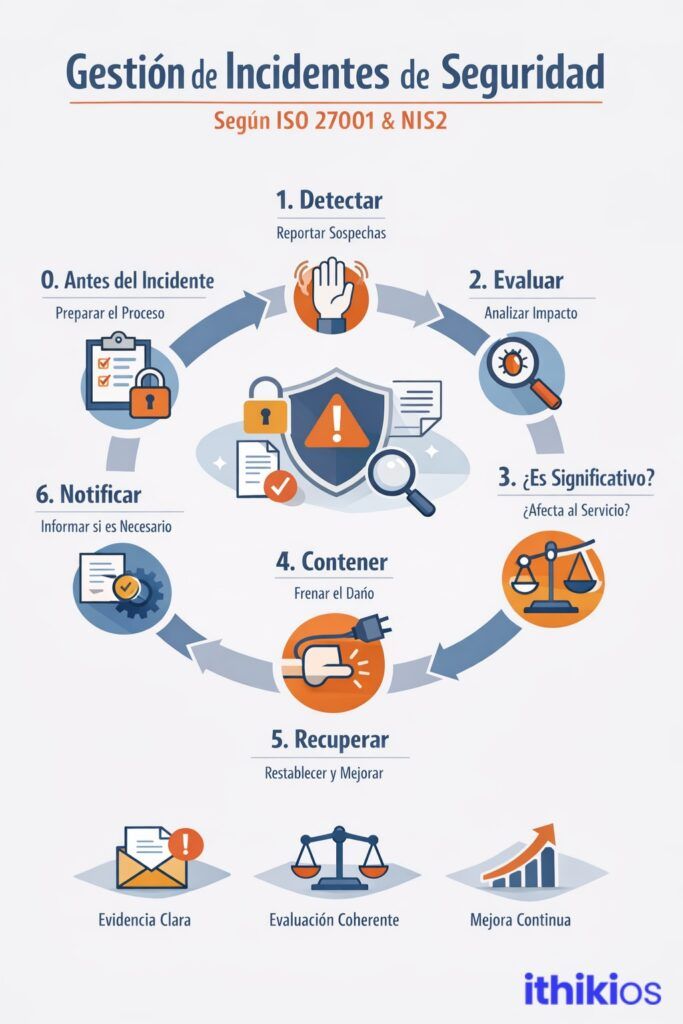
Étape 3 : Est-ce que cela a un sens sous NIS2 ? La question embarrassante
C’est là que la dimension réglementaire entre en jeu. Tous les incidents ne doivent pas être notifiés, et il est important de le comprendre, mais certains le doivent. Et le vrai risque n’est pas de notifier quand il le faut, mais de ne pas savoir comment justifier pourquoi vous avez décidé de ne pas le faire.
La directive NIS2 introduit la notion d’incident significatif et établit des critères spécifiques pour le déterminer : l’impact financier qu’il peut générer, l’impact sur les services essentiels, l’existence d’un accès malveillant pertinent ou la gravité des perturbations causées.
En pratique, la question est simple : l’incident a-t-il affecté – ou est-il susceptible d’affecter – la continuité du service, des données sensibles, un nombre significatif d’utilisateurs ou de tiers ?
Ces éléments permettent d’objectiver la décision, d’éviter qu’elle ne dépende uniquement de perceptions ou d’intuitions.
Cependant, plus que le critère lui-même, c’est le raisonnement documenté qui le sous-tend qui est important. Il ne s’agit pas seulement de conclure que quelque chose est significatif ou non, mais d’être capable d’expliquer pourquoi. Quelles informations ont été analysées, quel impact a été évalué, quels seuils ont été pris en compte et comment cette conclusion a été tirée.
Même si vous décidez qu’un incident n’est pas significatif, cette décision doit être enregistrée. En effet, dans le cadre du NIS2, l’absence de preuves ne signifie pas que vous avez agi correctement, mais que vous ne pouvez pas le prouver. Et dans le domaine de la réglementation, ce qui ne peut être prouvé n’existe tout simplement pas.
Étape 4. Contenir : arrêter d’abord l’aggravation
L’endiguement n’est pas une réparation. Il s’agit simplement d’empêcher les dommages de s’aggraver. Parfois, cela signifie isoler un système compromis. Ou de révoquer les informations d’identification susceptibles d’être exposées. Ou même de déconnecter temporairement un service pour enrayer la propagation. Il s’agit de décisions inconfortables, prises sous la pression et dans le bruit.
Et c’est précisément dans ce contexte que l’on oublie le plus facilement une chose essentielle : enregistrer ce qui est fait. La priorité est d’agir, de protéger, de stabiliser. Documenter peut sembler secondaire. Mais ce qui n’est pas écrit dans le feu de l’action peut rarement être reconstitué à froid.
Et, dans la mesure du possible, conservez les preuves avant de « nettoyer » le système : journaux, instantanés, courriels, hachages, captures ou tout élément permettant une reconstitution rigoureuse de ce qui s’est passé.
Chaque action doit laisser une trace claire : qui a pris la décision, à quel moment, quelle mesure concrète a été appliquée et dans quel but. Il ne s’agit pas d’un mécanisme défensif ou d’un exercice bureaucratique, mais d’un outil de compréhension. Car lorsque tout sera terminé, ce qui nous permettra d’apprendre – et de nous améliorer – ce n’est pas seulement ce qui a été fait, mais la capacité de comprendre pourquoi cela a été fait.
Étape 5 : Récupérer : de retour, mais en mieux
Récupérer ne signifie pas revenir le plus vite possible. Cela signifie revenir judicieusement. Il ne s’agit pas seulement de restaurer les systèmes et de reprendre les opérations, mais de le faire en ayant corrigé ce qui a permis à l’incident de se produire.
Si une vulnérabilité existait, elle doit être corrigée avant que l’environnement ne soit entièrement réactivé. Si des informations d’identification ont été compromises, les mécanismes d’authentification doivent faire l’objet d’une rotation et d’un réexamen. Si une faiblesse structurelle était évidente, elle doit être renforcée. Sinon, ce que nous appelons « reprise » n’est qu’une pause avant le prochain incident.
Un paradoxe fréquent apparaît ici : de nombreuses organisations gèrent assez bien l’urgence, mais négligent l’apprentissage. Elles se concentrent sur l’extinction de l’incendie et se réjouissent lorsque tout fonctionne à nouveau, mais ne consacrent pas la même rigueur à l’analyse de ce qui n’a pas fonctionné, des signaux qui ont été ignorés ou des décisions qui auraient pu être mieux prises.
La norme ISO 27001 insiste sur la nécessité de tirer des enseignements pour une raison très simple : les incidents ont tendance à se répéter. Les détails changent, mais pas toujours les causes profondes. Si vous ne transformez pas chaque incident en une contribution structurée à votre système d’amélioration continue, le prochain ne viendra pas seulement, mais il sera probablement plus coûteux et plus difficile à justifier auprès de la direction ou de l’autorité.
Étape 6 : Notification (le cas échéant) : lorsque l’incident n’est plus de votre ressort.
Il y a un moment où un incident n’est plus une affaire purement interne. En vertu de la directive NIS2, certains incidents doivent être signalés à l’autorité compétente dans des délais précis. Cette exigence change toute la donne.
À ce stade, il ne suffit plus d’avoir techniquement maîtrisé la situation. La manière dont vous avez classifié l’incident, le moment où vous avez considéré que vous aviez une connaissance raisonnable de sa portée, les mesures que vous avez prises à partir de ce moment-là et la manière dont vous avez évalué l’impact réel ou potentiel commencent à avoir de l’importance. Le récit technique devient également un récit de gestion et de responsabilité.
Et là, la direction ne peut plus se contenter d’être un spectateur. Elle doit être en mesure d’étayer la décision de notifier – ou de ne pas notifier – par des critères clairs et documentés. Car les conséquences ne sont pas seulement techniques ; elles peuvent être d’ordre réglementaire, réputationnel ou économique.
Même si vous décidez de ne pas notifier, l’exigence est la même : vous devez être en mesure de justifier cette décision de la même manière. Quels critères vous avez appliqués, quelles informations vous avez analysées et pourquoi vous avez conclu que le seuil de notification n’était pas atteint.
C’est ici que la gouvernance est réellement mise à l’épreuve.
Étape 7. Fermez formellement : ne le laissez pas disparaître tranquillement
Lorsque tout semble être rentré dans l’ordre, la tentation naturelle est de tourner la page et de passer à autre chose. Mais c’est là que de nombreuses organisations échouent. Nous pourrions dire qu’un incident qui n’est pas officiellement clôturé est, en réalité, un incident inachevé.
La clôture n’est pas une formalité administrative, c’est un exercice de rigueur. Elle implique d’analyser la cause profonde et de ne pas se contenter des symptômes visibles. Elle implique de consigner les décisions prises et leurs raisons, le temps nécessaire à la détection, à l’endiguement et au rétablissement, les actions correctives définies et les améliorations concrètes mises en œuvre pour réduire la probabilité de récurrence.
Et surtout, cette fermeture doit alimenter le système. Elle doit se traduire par des ajustements réels des procédures, des contrôles, de la formation ou des technologies. Si l’expérience ne change rien, il n’y a pas eu d’apprentissage, seulement une résolution.
En conclusion : il ne s’agit pas d’éviter les incidents
Les normes ISO/IEC 27001 et NIS2 n’exigent pas des systèmes parfaits. Elles exigent des organisations responsables. Des organisations qui partent du principe que les incidents ne sont pas une anomalie improbable, mais une possibilité réelle. Qui se préparent avant qu’ils ne se produisent. Qui, lorsqu’ils se produisent, agissent avec méthode plutôt qu’avec improvisation. Et qui, en temps voulu, peuvent expliquer calmement ce qui s’est passé, comment elles ont réagi et ce qu’elles ont appris.
Bien gérer un incident ne signifie pas le rendre invisible ou le minimiser jusqu’à ce qu’il semble sans importance. Cela signifie le rendre compréhensible pour quiconque doit l’analyser par la suite. C’est le rendre traçable dans chaque décision et chaque action. Et, surtout, c’est le rendre utile pour renforcer le système à l’avenir.
Il s’agit de transformer chaque incident en un plan d’amélioration : actions concrètes, responsables, délais et suivi.
La différence entre une organisation vulnérable et une organisation mature n’est pas l’absence d’incidents. C’est la qualité de ses décisions lorsque personne n’a toutes les réponses.
Lorsque cela se produit, l’incident n’est plus seulement un problème surmonté. Il devient quelque chose de plus précieux : la confirmation que le système de gestion n’est pas décoratif, mais qu’il fonctionne dans la pratique, même sous pression.

