
C’è qualcosa che raramente viene detto ad alta voce all’interno delle organizzazioni: a tutti noi piace segretamente quando non succede nulla. Nessuna violazione. Nessun ransomware. Che nessuno clicchi dove non dovrebbe. È comprensibile, ma poco realistico.
ISO 27001 e NIS2 partono da un’idea molto più matura: gli incidenti accadranno. La differenza non sta nell’evitarli, ma nel modo in cui reagiamo quando accadono. E, soprattutto, se siamo in grado di dimostrare di aver reagito con giudizio, controllo e prove dopo l’evento.
Fase 0. Prima dell’incidente
Uno degli errori più grandi è pensare che la gestione degli incidenti inizi nel momento in cui qualcuno si accorge che c’è un problema. In realtà, inizia molto prima. Inizia quando l’organizzazione ha preso decisioni chiare su come agire il giorno in cui si manifesta il problema: chi riceve la notifica iniziale, chi la analizza e la classifica, chi ha l’autorità di decidere i passi successivi e in base a quali criteri, e come ogni azione e prova verrà registrata.
Se questo non viene definito in anticipo, il primo incidente grave non sarà solo un incidente di sicurezza, ma anche un episodio di disordine organizzativo. Ci saranno dubbi sulle responsabilità, ritardi nel processo decisionale, messaggi contraddittori e probabilmente una tracciabilità incompleta dell’accaduto. E nella cybersecurity, il disordine moltiplica l’impatto.
Ecco perché norme come la ISO 27001 non si limitano a raccomandare le buone pratiche, ma richiedono l’esistenza di un processo formale di gestione degli incidenti. E standard come il NIS2 fanno un ulteriore passo avanti: richiedono non solo che tale processo esista sulla carta, ma che funzioni nella pratica e che l’organizzazione sia in grado di dimostrarlo con prove chiare, registrazioni e risultati misurabili.
Ma c’è di più: secondo il NIS2, la responsabilità non è solo tecnica. L’alta dirigenza e, se del caso, il consiglio di amministrazione, devono essere in grado di dimostrare di aver supervisionato, compreso e sostenuto il sistema di gestione degli incidenti. Non si tratta solo di avere una procedura, ma di avere una vera e propria governance sulla gestione del rischio.
Fase 1. Rilevamento: qualcuno deve essere in grado di alzare la mano.
Di solito tutto inizia con qualcosa di piccolo. Uno strano comportamento che non quadra, un accesso fuori orario che attira la tua attenzione, un sistema che risponde più lentamente del solito senza un motivo apparente. Segnali deboli, quasi impercettibili, che potrebbero essere una semplice anomalia… o l’inizio di qualcosa di più grande.
La persona che lo rileva non deve sapere se è grave, né deve confermare se si tratta davvero di un incidente. La sua responsabilità non è quella di fare una diagnosi, ma di sapere dove segnalarlo. Questo dettaglio apparentemente secondario trasforma completamente la cultura dell’organizzazione.
Quando le persone capiscono che segnalare non significa “mettersi nei guai” ma essere parte attiva del sistema di protezione, l’organizzazione diventa più resiliente. Riduce i tempi di reazione, evita inutili silenzi e crea una rete di allerta precoce molto più efficace di qualsiasi strumento tecnologico.
Il modo migliore per rilevarli è avere un modulo pubblico per individuare e identificare gli incidenti il prima possibile. Una buona alternativa è il modulo ithikios Incident Manager.
Passo 2. Valutare: fermarsi, pensare, ordinare
Questo secondo passo è quello in cui inizia la maturità. Non si tratta di reagire in modo drastico o di correre senza direzione. Si tratta semplicemente di fermarsi un attimo e di porsi due domande molto specifiche: quale impatto può avere l’incidente e con quale urgenza dobbiamo agire.
Sembra ovvio, ma a questo punto molte organizzazioni inciampano: iniziano a implementare azioni prima di aver capito cosa sta succedendo. Qualcosa viene “fatto” per inerzia, pressione o paura di rimanere fermi. Il problema arriva dopo, quando qualcuno chiede perché sono state intraprese determinate azioni, perché è stata fatta un’escalation, perché un sistema è stato isolato, perché è stato comunicato – o non è stato comunicato – e allora non c’è una risposta strutturata, ma solo spiegazioni improvvisate.
La ISO 27001 insiste su un processo. La NIS2 si concentra su una valutazione motivata. In pratica, questo significa che ogni decisione deve poter essere spiegata in modo semplice: cosa si sapeva al momento, come è stato valutato l’impatto, perché è stato considerato urgente (o meno) e come questa classificazione ha portato all’azione. Non come esercizio burocratico, ma come base di una risposta coerente e difendibile ai revisori, alle autorità o al consiglio stesso.
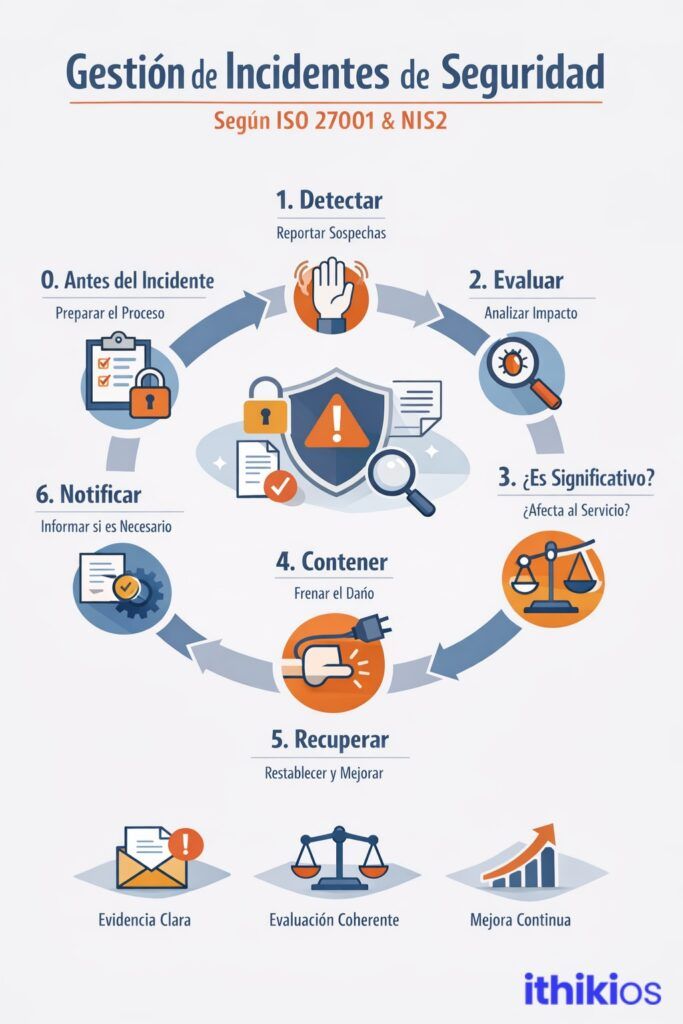
Passo 3. Ha senso sotto NIS2? La domanda scomoda
È qui che entra in gioco la dimensione normativa. Non tutti gli incidenti devono essere notificati, ed è importante capirlo, ma alcuni sì. Il vero rischio non è quello di notificare quando è necessario, ma di non saper giustificare il motivo per cui si è deciso di non farlo.
La Direttiva NIS2 introduce il concetto di incidente significativo e stabilisce criteri specifici per determinarlo: l’impatto finanziario che può generare, l’impatto sui servizi essenziali, l’esistenza di un accesso doloso o la gravità delle interruzioni causate.
In pratica, la domanda è semplice: il problema ha interessato – o potrebbe interessare – la continuità del servizio, i dati sensibili, un numero rilevante di utenti o di terzi?
Questi elementi aiutano a oggettivare la decisione, evitando che dipenda esclusivamente da percezioni o intuizioni.
Più importante del criterio in sé, tuttavia, è il ragionamento documentato che lo sostiene. La chiave non è solo concludere se qualcosa è significativo o meno, ma essere in grado di spiegare perché. Quali informazioni sono state analizzate, quale impatto è stato valutato, quali soglie sono state considerate e come si è giunti a tale conclusione.
Anche quando decidi che un incidente non è significativo, questa decisione deve essere registrata. Perché secondo il NIS2, l’assenza di prove non implica che tu abbia agito correttamente, ma che tu non possa provarlo. E nel campo della regolamentazione, ciò che non può essere provato semplicemente non esiste.
Fase 4. Contenere: prima fermare il peggioramento
Contenere non significa riparare. Si tratta semplicemente di evitare che il danno cresca. A volte significa isolare un sistema compromesso. O revocare le credenziali che potrebbero essere esposte. O addirittura disconnettere temporaneamente un servizio per bloccare la diffusione. Si tratta di decisioni scomode, prese in mezzo alla pressione e al rumore.
Ed è proprio in questo contesto che è più facile dimenticare qualcosa di essenziale: registrare ciò che viene fatto. La priorità è agire, proteggere, stabilizzare. Documentare può sembrare secondario. Ma ciò che non viene scritto nella foga del momento difficilmente potrà essere ricostruito a freddo.
E, quando possibile, conserva le prove prima di “pulire” il sistema: log, istantanee, email, hashtag, catture o qualsiasi elemento che permetta una ricostruzione rigorosa di ciò che è accaduto.
Ogni azione dovrebbe lasciare una traccia chiara: chi ha preso la decisione, in quale momento, quale misura concreta è stata applicata e per quale scopo. Non come meccanismo difensivo o come esercizio burocratico, ma come strumento di comprensione. Perché quando tutto sarà finito, ciò che ci permetterà di imparare – e migliorare – non sarà solo ciò che è stato fatto, ma anche la capacità di capire perché è stato fatto.
Fase 5. Recupero: indietro, ma meglio
Recuperare non significa tornare il prima possibile. Significa tornare con criterio. Non si tratta solo di ripristinare i sistemi e riprendere le operazioni, ma di correggere ciò che ha permesso il verificarsi dell’incidente.
Se esiste una vulnerabilità, è necessario correggerla prima di riattivare completamente l’ambiente. Se le credenziali sono state compromesse, i meccanismi di autenticazione devono essere ruotati e rivisti. Se è stata evidenziata una debolezza strutturale, questa deve essere rafforzata. Altrimenti, quello che chiamiamo “recupero” è solo una pausa prima del prossimo incidente.
In questo caso si verifica un paradosso frequente: molte organizzazioni gestiscono ragionevolmente bene l’urgenza, ma trascurano l’apprendimento. Si concentrano sullo spegnimento dell’incendio e festeggiano quando tutto torna a funzionare, ma non dedicano lo stesso rigore all’analisi di ciò che è andato storto, di quali segnali sono stati ignorati o di quali decisioni avrebbero potuto essere prese meglio.
La ISO 27001 insiste sulla necessità di trarre insegnamenti per un motivo molto semplice: gli incidenti tendono a ripetersi. Cambiano i dettagli, ma non sempre le cause principali. Se non trasformi ogni incidente in un input strutturato per il tuo sistema di miglioramento continuo, il prossimo non solo arriverà, ma sarà probabilmente più costoso e più difficile da giustificare alla direzione o alle autorità.
Fase 6. Notifica (se applicabile): quando l’incidente non è più solo tuo.
C’è un momento in cui un incidente non è più una questione puramente interna. Secondo la direttiva NIS2, alcuni incidenti devono essere segnalati all’autorità competente entro scadenze specifiche. Questo requisito cambia l’intero discorso.
A questo punto, non è più sufficiente aver contenuto tecnicamente la situazione. Inizia a essere importante come hai classificato l’incidente, in quale momento hai ritenuto di avere una ragionevole conoscenza della sua portata, quali azioni hai intrapreso da quel momento in poi e come hai valutato l’impatto reale o potenziale. Il racconto tecnico diventa anche un racconto di gestione e responsabilità.
In questo caso, la direzione non può più essere uno spettatore. Deve essere in grado di supportare la decisione di notificare – o non notificare – con criteri chiari e documentati. Perché le conseguenze non sono solo tecniche: possono essere normative, reputazionali o economiche.
Anche se decidi di non notificare, il requisito è lo stesso: devi essere in grado di giustificare tale decisione in modo altrettanto valido. Quali criteri hai applicato, quali informazioni hai analizzato e perché hai concluso che non soddisfano la soglia di notifica.
È qui che la governance viene messa davvero alla prova.
Passo 7. Chiudi formalmente: non lasciare che scompaia silenziosamente
Quando tutto sembra essere tornato alla normalità, la tentazione naturale è quella di voltare pagina e andare avanti. Ma è qui che molte organizzazioni falliscono. Si potrebbe dire che un incidente non formalmente chiuso è, in realtà, un incidente non concluso.
La chiusura non è una formalità amministrativa, ma un esercizio di rigore. Comporta l’analisi della causa principale e non si accontenta dei sintomi visibili. Si tratta di registrare quali decisioni sono state prese e perché, quanto tempo è stato necessario per individuare, contenere e recuperare, quali azioni correttive sono state definite e quali miglioramenti concreti sono stati implementati per ridurre la probabilità che il problema si ripeta.
E, soprattutto, questa chiusura deve confluire nel sistema. Deve tradursi in un reale adeguamento delle procedure, dei controlli, della formazione o delle tecnologie. Se l’esperienza non cambia nulla, non c’è stato alcun apprendimento, ma solo una risoluzione.
In conclusione: non si tratta di evitare gli incidenti.
ISO/IEC 27001 e NIS2 non richiedono sistemi perfetti. Richiedono organizzazioni responsabili. Organizzazioni che partono dal presupposto che gli incidenti non sono un’improbabile anomalia, ma una possibilità reale. Che si preparino prima che accadano. Che, quando accadono, agiscono con metodo piuttosto che con improvvisazione. E che, col tempo, siano in grado di spiegare con calma cosa è successo, come hanno reagito e cosa hanno imparato.
Gestire bene un incidente non significa renderlo invisibile o minimizzarlo fino a farlo sembrare irrilevante. Significa renderlo comprensibile a chiunque debba analizzarlo in seguito. Significa renderlo rintracciabile in ogni decisione e in ogni azione. E, soprattutto, significa renderlo utile per rafforzare il sistema in futuro.
E significa trasformare ogni incidente in un piano di miglioramento: azioni concrete, responsabili, scadenze e follow-up.
La differenza tra un’organizzazione vulnerabile e un’organizzazione matura non è l’assenza di incidenti. È la qualità delle sue decisioni quando nessuno ha tutte le risposte.
Quando ciò accade, l’incidente non è più solo un problema superato. Diventa qualcosa di più prezioso: una conferma che il sistema di gestione non è decorativo, ma funziona nella pratica, anche sotto pressione.

